
數據處理 Data Processing對於AI的重要性為何?看台灣AI應用生態系
數據處理 Data Processing對於AI的重要性為何?
2023台灣AI生態系地圖
隨著這一年來AI人工智慧的躍進式發展,市場對於AI重視程度不斷提升,甚至各行各業都急著投入,也使得AI發展的生態系更加活躍、競爭、細化、整合。
 AI發展需求使得數據處理的重要性日益提升
AI發展需求使得數據處理的重要性日益提升AI 發展的重要關鍵
回到理論與實務,AI發展最重要的一環是數據處理(Data Processing)——這就像是廚師做菜一樣,沒有好食材、食材沒有處理好,後面再怎麼料理調味也難做出好菜。尤其當AI要落地到不同產業發展時,數據的質量更是能否快速成功實現的最大關鍵。
什麼是數據處理
數據處理(Data Processing)包括數據清洗和預處理,這是確保數據品質的重要步驟。通過去除缺失值、處理重複數據和標準化特徵,可以確保模型在訓練和預測過程中處理乾淨、一致的數據。
總之,數據處理在AI發展中是一個不可或缺的環節,對於確保模型的效能、可靠性和適應性都有著重要的影響。透過更多、更高質量的數據,可以實現更強大、更靈活且更具預測能力的人工智慧應用生態。
數據處理對於AI發展的三大價值
簡單來說,其價值主要可以體現在三個面向:
- 數據品質
- 即時性
- 海量數據
1. 數據品質
人工智慧模型的性能受到訓練數據品質的直接影響。高品質的訓練數據能夠提高模型的準確性和泛化能力,減少資料集中雜訊可能造成過度擬合(Overfitting)的情況,提高模型的預測效果,也能降低對數據量的需求。
2. 即時性
在人工智慧應用中,即時性至關重要,特別是在需要做出迅速決策的場景下,例如金融交易、醫療診斷等。數據處理有助於實現對即時數據的快速處理和分析,使系統能夠達成實時預測和反饋,提高系統的效能和靈活性。
3. 海量數據
深度學習模型通常需要足夠大量的數據進行訓練,以更好地學習各種特徵和複雜的模式。數據處理能幫助更有效地處理和管理大規模的數據集,確保模型在控制成本下獲得足夠的訓練樣本,以優化、提升模型的性能與預測準確性,能夠更好地分析未知數據。
AI發展還有哪些領域
隨著 AI 技術深化,AI產業又可細分為不同領域,根據人工智慧科技基金會(AIF)與AppWorks、台灣智慧雲端服務(簡稱台智雲,TWS)合作發布的2023年「台灣 AI 生態系地圖」,主要可分為三大面向:
- AI發展工具: 包含AutoML/MLops機器學習平台、AI晶片與處理器、數據處理、數據貼標、深度學習加速器、基礎模型等。
- 跨產業應用: AI越來越能在不同的日常工作場景中協助我們,這也使得一些跨領域的泛性應用與技術日益被重視,包含自然語言處理(NLP)、Computer Vision、雲端技術、邊緣運算、環境保護、資安等。
- 產業深度應用: AI可運用的產業領域越來越廣,包含電商、金融科技、醫療健康、行銷科技等領域,近年來更逐漸擴大,包含自駕車、無人機、能源、通用型機器人、教育、法律科技等多面向。
其中, LnData 便是屬於數據處理的服務提供者,協助品牌將AI訓練所需要的龐大、非結構化、來自不同來源的數據進行數據清理與整合,甚至部分也包含分析、模型訓練與部屬等任務。
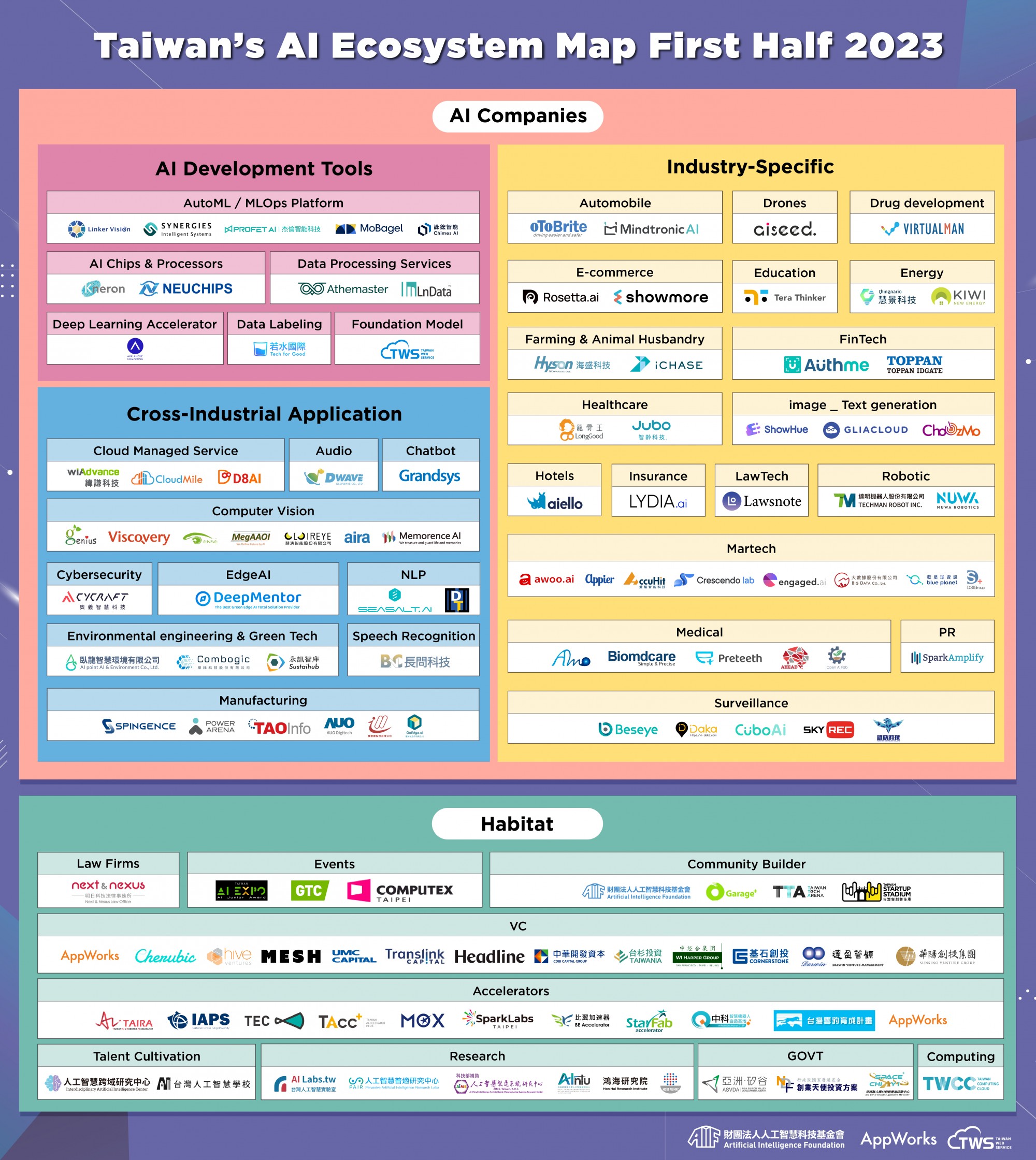 台灣 AI 生態系地圖
台灣 AI 生態系地圖LnData 做為台灣的數據顧問公司,提供多元且完整的數據服務,包含從數據的收集、清理、分析與應用,可協助企業針對不同的數據需求提供對應的解決方案。例如,可透過數據中台,打造一站式的數據管理平台,更好地將大量數據快速處理,以應用到如行銷、金融、ESG等不同場景。
企業如果想投入AI應用該怎麼做
不同企業的規模與擁有的人力、技術、算力等資源不同,因此想自己投入AI的發展、訓練自己的模型,以落地運用到企業日常營運當中,除了透過ChatGPT等開源工具之外,其實還有不同的方法與路徑。
不同企業想深化AI應用
- 企業自有數據團隊,但想要提高效率、降低成本、擴大彈性:與數據服務供應商建立合作關係。
- 企業沒有數據團隊,但也想導入AI:透過數據處理或數據收集等服務,補齊缺乏數據、與難以負荷龐大訓練數據等技術門檻問題。
- 立即連繫我們




