
2023 年想成為數據工程師的 12 項必備技能
2023 年想成為數據工程師的 12 項必備技能
終極完整版數據工程師技能盤點
大數據時代來臨,企業數位轉型的需求應運而生,因此數據工程師(資料工程師)在企業中所扮演的角色也日益重要。今天讓我們來盤點要成為數據工程師,強烈推薦要學的 12 項必備技能,來幫助企業使用數據創造價值!
 數據科學家(資料科學家)是許多企業的搶手人才
數據科學家(資料科學家)是許多企業的搶手人才成為數據工程師的 12 項必備技能:
- 基本技能(程式語言與資料架構)
- 網路概念
- 資料庫 Database
- 數據湖 Data Lake 與物件存儲
- 數據倉儲 Data Warehouse
- 分散式系統
- 數據處理
- 機器學習 Machine Learning
- 作業編排管理
- 前端與儀表板
- 後端框架
- 自動化與部署
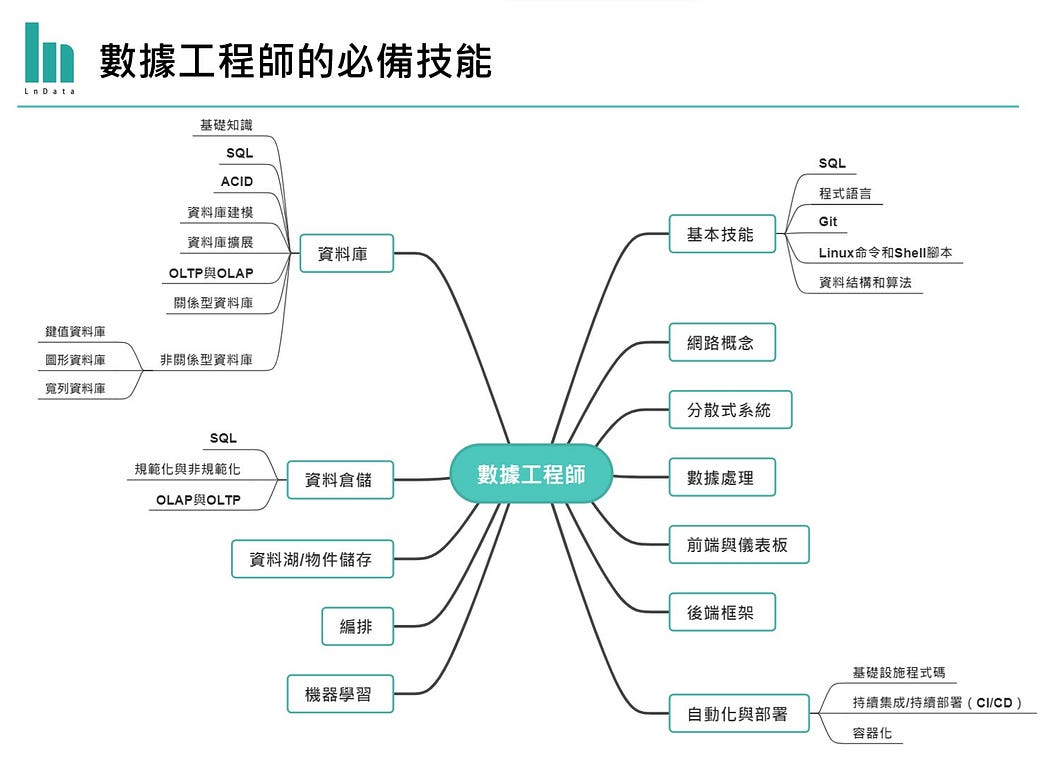 數據工程師的必備技能樹 (Source: Anuj Syal)
數據工程師的必備技能樹 (Source: Anuj Syal)一、基本技能
首先,以下是最基本的必修技能,也是想進入這個行業需要的優先入手技能,包含:
- SQL:SQL即”Structured Query Language”,也稱做「結構化查詢語言」,是一種用於管理和查詢關聯式資料庫的語言,用於處理和操作大量數據。它允許數據工程師對資料庫執行各種操作,如數據檢索、修改和定義,且幾乎所有資料庫和數據倉儲都使用SQL。
- 程式語言:數據工程師必備技能當然包括使用不同的程式語言來處理數據,如 R、Scala、Java等,但首推 Python,因為Python容易上手,並且擁有許多免費且開源的資料科學工具和資源,使其成為處理數據相關工作的理想選擇。不僅如此,Python還有豐富的開發者社群,讓你輕鬆找到相關的學習資源和解決問題的方法。
- Git:即”Global Information Tracker”,Git是版本控制的重要工具,可以追蹤、保存和管理軟體代碼的所有更改和操作,幫助資料工程師協作開發數據工程項目,並確保團隊成員之間的協同工作,可避免有人亂改或誤刪代碼。
- Linux指令和Shell腳本:Linux是一種常用的作業系統,數據工程師經常使用它來處理數據,常見的版本如Ubuntu、Fedora。熟悉Linux命令(例如cd、pwd、cp、mv等)和Shell腳本可以幫助數據工程師自動化任務、管理伺服器和處理大量數據。
- 資料結構和演算法:數據工程師需要對資料結構(Data Structures)和演算法(Algorithms)有足夠的理解和解決問題的技能,以優化數據處理和分析。初學者可透過初級到中難度的LeetCode問題進行練習。
二、網路概念
由於現在大半數據都在線上,因此工程師常需接觸與處理VM(虛擬機)、伺服器和 API(應用程式介面),而此時就需要對 IP(互聯網協議)、DNS(域名伺服器)、VPN 等基本網路概念有基本了解。
延伸閱讀:API是什麼
三、資料庫
資料庫是按照數據結構來組織、存儲和管理數據的倉庫,相關概念包含:
- 基礎知識:資料庫是存儲數據的空間,包含表(Table)、行(Column)、列(Row)、鍵(Key)、連接(Join)、合併(Merge)和模式(Schema)等基本概念。
- SQL:雖然前面提過了,但要知道在使用這些資料庫時,SQL可說是最泛用也最不可或缺的語法,因此這邊再提一次。。
- ACID:是原子性(Atomicity)、一致性(Consistency)、隔離性(Isolation)、持久性(Durability)的縮寫,旨在確保數據操作的有效性和穩定性。
- 資料庫建模:指在設計資料庫時考慮如何組織資料的過程,包括星型模式、平面設計和雪花模式等不同方法。
- 資料庫擴展:包括垂直擴展和水平擴展,它們用於增加資料庫的性能和容量。
- OLTP與OLAP:OLAP(在線分析處理)、OLTP(在線交易處理)是不同類型的數據處理系統。OLTP是設計用於處理日常業務交易和交互式操作的系統;OLAP則是設計用於分析和探索大量數據的系統。
- 關係型資料庫:Relational Database,是大多數應用程式使用的傳統資料庫,用於結構化數據。常用的資料庫有PostgreSQL和MySQL。
- 非關係型資料庫:Non-relational Database,也稱為NoSQL資料庫。跟傳統的關聯型資料庫不同,它們不使用固定的表格模式,而是以更靈活的方式存儲數據,適合處理大量非結構化數據。非關係型數據還可分為三種類型:
- 鍵值資料庫:如Redis、DynamoDB、FireBase
- 圖形資料庫:如Neo4j、ArangoDB
- 寬列資料庫:如Apache Cassandra、Google BigTable
四、數據湖 Data Lake 與物件存儲
數據湖是一種大規模集中式數據存儲系統,它允許組織以原始、半結構化或非結構化的形式存儲數據,而無需建立嚴格的資料結構。這意味著數據湖可以包含來自不同來源、不同格式和不同質量的數據,可以是文本、圖像、影音等,也包含報表、視覺化、資料分析、機器學習等轉換後資料。
數據湖通常使用分佈式或物件存儲(Object Storage)系統來存儲大量數據,如Hadoop HDFS、Amazon S3等。數據以原始文件或對象的形式存儲,每個對象都包含數據本身、元數據(metadata)和唯一識別子。這種方式使得數據能夠以平面結構組織,並且具有元數據以描述數據的特徵和用途,能夠更好地管理和查詢數據。
五、數據倉儲 Data Warehouse
數據倉儲(Data Warehouse)是一種專為組織和管理大量數據而設計的數據存儲和管理系統。它的主要目標是將來自不同來源的數據整合到一個統一的、易於查詢和分析的資料庫中,以支持企業的決策制定、報告和分析需求。例如 Google 的 BigQuery、AWS Redshift、Azure Synapse、Snowflake、ClickHouse 和 Hive。須了解的相關概念包含:
- SQL(略)
- 規範化與非規範化:在數據倉儲中,數據可以以規範化(Normalized)或非規範化(Denormalized)的方式進行組織和存儲,具體選擇取決於業務需求和查詢性能的考慮。規範化主要為求消除數據中的冗余或不一致性;而非規範化則是將數據合併到一個表中以提高數據更改速度。
- OLAP與OLTP(略)
六、分散式系統
包含大數據、Hadoop、分佈式文件系統、MapReduce等概念。在分散式系統中,多台機器(稱為節點或伺服器)組成叢集並共同協作,這些機器可以在不同的地方執行,彼此通信並共同完成任務。分散式系統的好處是可提高性能、可用性和擴展性,同時減少單點故障的風險。
由於其複雜性,這些系統擁有各自獨立的技術組件。因此,為了開發與佈署這些系統,數據工程師需要使用叢集管理技術或工具,如Kubernetes、Databricks,或者自行建立Hadoop叢集等。此外,還有許多開源技術可供利用。
七、數據處理
數據處理是指使用程式語言來轉換數據的過程,這包括清理數據以及驗證數據的準確性。在進行數據處理時,通常會使用各種工具和框架,具體選擇取決於任務的性質和規模。
以下是一些常用的數據處理工具和框架:
- Pandas:Pandas是一個好用的Python套件,常被用於處理和分析數據。它提供了豐富的數據結構和函數,適合用於數據轉換和清理。
- SQL:(沒錯,又是它)由於多數數據倉庫支持SQL語言,因此SQL是一個常用的工具,用於執行數據轉換操作,尤其適用於處理結構化數據。
- Spark:Apache Spark是一個用於大數據處理的強大框架,它提供了分佈式數據處理和分析計算。Spark通常用於處理大規模數據轉換操作,性能高且具有可擴展性。
- Spark Streaming:Spark Streaming是Spark的一個模塊,用於處理流式數據。它可以實時處理數據流,非常適合需要即時分析的應用。
 Pandas是資料科學必備的Python套件
Pandas是資料科學必備的Python套件八、機器學習 Machine Learning
機器學習(Machine Learning)是一種人工智慧(AI)的子領域,它教導電腦如何從數據中學習,以自動改進和做出決策,而不需要明確的程式指令。機器學習可以應用於多個領域,如圖像辨識、語音識別、自然語言處理、醫療診斷、金融預測以及自駕車技術等。
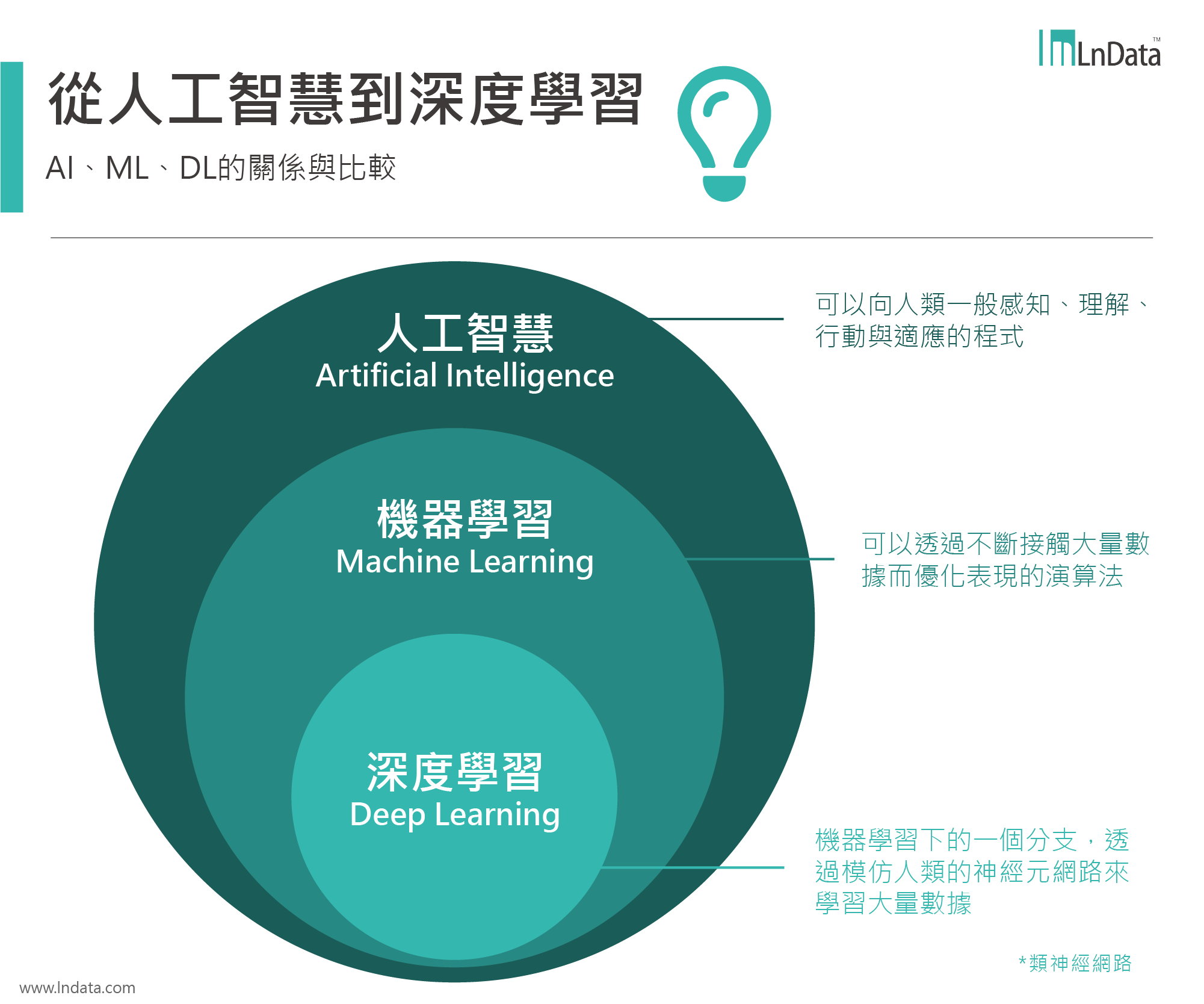 人工智慧、機器學習、深度學習都是資料科學中的熱門領域
人工智慧、機器學習、深度學習都是資料科學中的熱門領域延伸閱讀:文組也該懂的機器學習!從行銷、管理到金融都有用
對於數據工程師來說,了解機器學習的不同類型,包括監督學習、非監督學習和增強學習,以及相關的模型(如邏輯回歸、決策樹、K-最近鄰算法等)很重要。他們需要知道何時應該使用哪種模型,並學會處理數據、調整模型參數,以及評估模型的預測準確性。
操作機器學習的平台有Vertex AI、Kubeflow等,這些平台可以協助數據工程師輕鬆部署模型,並構建更準確的工作流程,幫助數據科學家做出更精確的決策。
 Vertex AI 是Google Cloud上的一個機器學習平台
Vertex AI 是Google Cloud上的一個機器學習平台此外,還有一些集成平台可讓數據工程師將工作流程整合到一個地方,如AWS Sagemaker、Databricks和Hugging Face等。這些平台通過共用的應用程式接口和圖形界面,使應用軟體功能不受特定硬體、作業系統、網路協議或資料庫管理系統的限制。
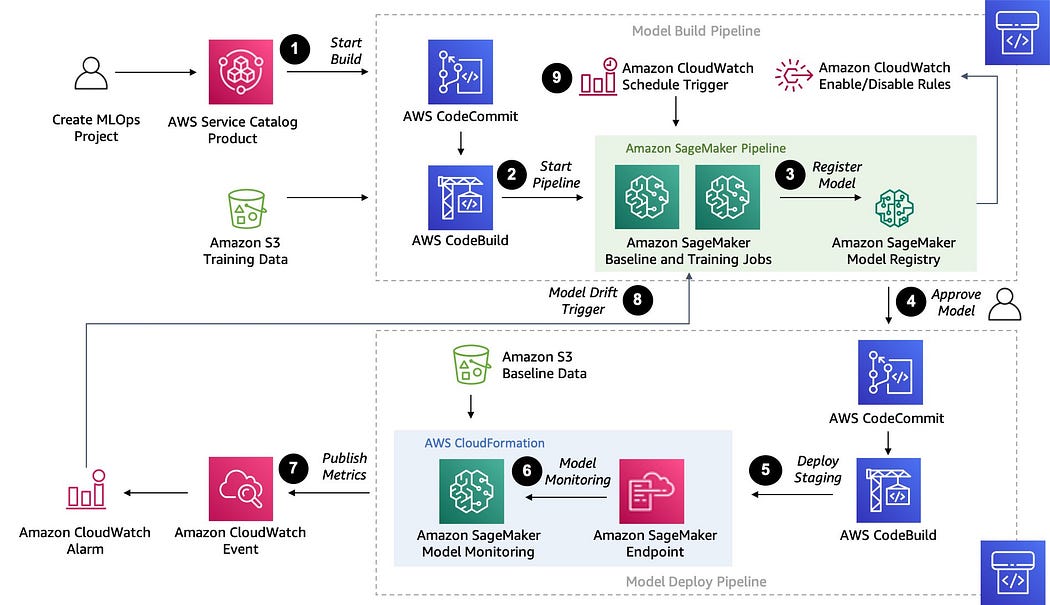 AWS Sagemaker也是不少人的ML開發選擇(Source: AWS)
AWS Sagemaker也是不少人的ML開發選擇(Source: AWS)九、作業編排管理
編排(orchestration)是一種用於管理和協調組織各種任務和工作流程的方法。它幫助我們確保工作按照預定的順序執行,以達到我們的目標。
最佳的編排工具之一是Airflow。它使用基於Python的有向無環圖(DAG)來記錄工作流程,讓您可以清楚地定義和規劃工作。Airflow特別適用於複雜的工作流程,並且在大數據和數據工程領域中廣泛使用。
其他工具包含Luigi、Nifi和Jenkins。每個工具都有其獨特的特點和使用場景,可以根據你的項目需求來選擇適合的編排工具,可以幫助數據工程師自動化和管理各種任務,提高工作效率。
十、前端與儀表板
前端和儀表板(deshboard)是用來展示數據結果和互動的工具。它們讓我們能夠以圖表、圖像和表格的形式呈現數據,並讓用戶與數據進行互動。
舉例來說,Jupyter Notebook 是一種常用的工具,它可以幫助數據科學家和分析師在筆記本中直接進行數據分析並建立視覺化圖表。
 Jupyter Notebook是好用的互動式開發工具,是許多資料科學工作者選擇
Jupyter Notebook是好用的互動式開發工具,是許多資料科學工作者選擇此外,儀表板或所謂BI工具如 PowerBI 和 Tableau,以及 Python 套件如Dash 和 Gradio,也被廣泛使用。這些工具允許我們建立互動性強的儀表板,讓用戶輕鬆探索數據,查看不同的視覺化結果,並根據需求進行操作。
十一、後端框架
後端框架與軟體工程有關,它們有助於構建網站和應用程序的後端部分。舉例來說,如果您想建立一個網站或應用,可能需要一個後端框架來處理用戶發出的請求、管理資料庫,以及提供信息給前端顯示。
基於 Python 的後端框架包含 Flask、Django 和 FastAPI 等。Flask 是一個輕量級的框架、Django則提供了更多的內置功能、FastAPI 則專注於建立API。
除了這些,還有一些雲端技術可供使用,例如G oogle Cloud Platform(GCP)的 Vertex AI API 和 AutoML APIs,這些技術可以用於模型部署和機器學習應用。
 Flask 是一個 Python 網頁應用程式框架,因輕量靈活而受許多開發者喜愛
Flask 是一個 Python 網頁應用程式框架,因輕量靈活而受許多開發者喜愛十二、自動化與部署
自動化和部署是指使用不同的工具和技術,來讓程式碼的建立和執行過程更加自動化和簡化,有助於提高效率、降低錯誤,並讓應用程式更容易管理和維護。
這個過程包括以下幾個主要方面:
- 基礎設施即程式碼(Infrastructure as Code):這是使用工具如Terraform、Ansible和Shell指令來管理和配置伺服器和基礎設施的過程。這些工具可讓你將基礎設施視為程式碼來處理,使其更易管理和自動化。
- 持續集成/持續部署(CI/CD):指透過GitHub Actions和Jenkins等工具來自動化程式碼的測試、集成、部署和交付的過程。有助於確保程式碼的品質,並使新功能能夠快速部署到生產環境。
- 容器化:即使用Docker和Docker Compose等工具,將應用程式和其相關的依賴項打包成容器的過程,可使應用程式在不同環境中更容易部署和執行。
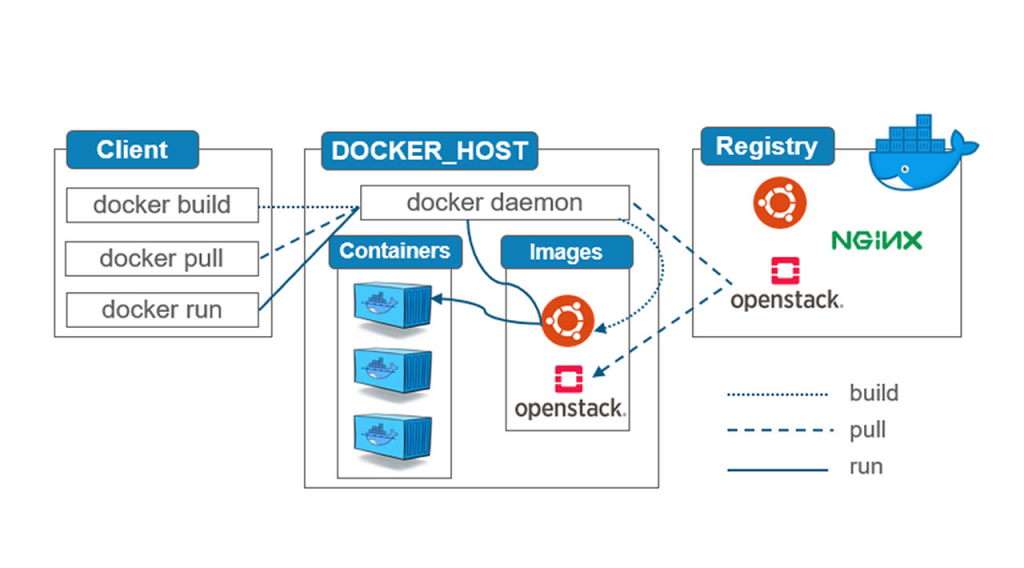 Docker工作流程示意
Docker工作流程示意如何開始?
在學生可以學習統計、資工、資料科學等科系的課程,或是透過相關實習或競賽來摸索對此領域的興趣。此外,網路上有許多付費課程、YouTube上的免費資源,也可以在kaggle等平台取得更多練習與交流機會,LnData也會定期分享相關知識、技巧或資源!
要記得,這些相關技術日新月異,即使是正在工作中的數據工程師也必須時時學習與了解最新技術。相對的,正因為技術不停在改變,你也不需要強求把上面所有技能練到精通,而是掌握重要的基本概念與保持開放的學習態度。
數據工程師可以為企業做什麼?
數據工程師日常就是與數據打交道,主要包含收集、讀取、清理,探勘與管理企業的資料,以抓取符合企業分析需求的數據。這些數據則能進一步透過機器學習、演算法,產生更有價值的結果或應用方式,幫助企業做出更好的決策、優化業務流程,例如降低成本、提高獲益、優化產品、留住熟客及開發新客群。因此,數據工程師對於企業的重要性不言而喻。
 溝通與團隊協作也是數據工程師的重要能力
溝通與團隊協作也是數據工程師的重要能力然而,企業想挖掘數據最大價值,並不能只靠數據工程師。一個完整的數據團隊,通常包含數據工程師、數據科學家、數據分析師三種角色,各司其職、專業分工。舉例來說,LnData做為台灣的數據顧問團隊,便有專門負責數據產品開發、部屬,以及管理客戶數據的數據工程師;負責資料探勘與機器學習的資料科學家;以及分析數據為客戶洞察,並視覺化呈現結果的數據分析師。他們在日常工作流程中扮演各自的角色,互相協作,完成各種不同的專案——這也是為何我們最後要強調,除了技術以外,溝通與協作等軟技能也非常重要!



