資料貼標是什麼?AI 訓練背後最關鍵的一步
資料貼標是什麼?AI 訓練背後最關鍵的一步
精準行銷的起點,也是 AI 模型能否學會的關鍵
一、什麼是資料貼標(Data Labeling)?
資料貼標又稱資料標記或資料註記,是機器學習流程中的核心前置作業。其核心概念是:對原始數據賦予結構化的語義標籤,使 AI 模型能夠從中識別規律、學習分類邏輯,並在面對未知數據時做出有效預測。
沒有經過貼標的原始數據,對模型而會是難以解讀的雜訊。無論是圖像辨識、自然語言處理,還是顧客行為預測,所有監督式學習的基礎都建立在標記品質夠高、涵蓋範圍夠廣的訓練資料集上。這也是為什麼業界常說:「數據的品質是決定了模型上限的關鍵。」
▌ AI 訓練四步驟

要理解資料貼標在整個 AI 流程中扮演的角色,可以從以下四個階段來看:
1. 資料收集:蒐集原始數據作為訓練素材,來源涵蓋顧客購買紀錄、瀏覽行為、問卷回答,或圖片、文字、語音等非結構化資料。
2.資料貼標:針對每一筆原始數據賦予語義標籤。例如將特定顧客標記為「高消費族群」或「流失風險」,或將一段文字標記為「正面情緒」,讓模型能夠學習辨別。
3.模型訓練:將大量標記完成的數據輸入 AI 模型,透過反覆學習找出數據中的規律與預測邏輯。
4.預測與應用:完成訓練的模型即可對新進的未知數據自動做出分類與預測,驅動後續的自動化決策。
二、從「資料貼標」到「顧客貼標」
資料貼標的概念應用到行銷場景,對應的就是「顧客貼標」。兩者的核心邏輯很相似:將非結構化或半結構化的原始數據,轉化為系統與模型可識別、可運算的語義標籤。
顧客的消費行為、瀏覽習慣、互動頻率,本身是非結構化的訊號。顧客貼標的工作,就是將這些訊號轉譯為明確的屬性標籤,建立每一位顧客的數位輪廓,讓行銷系統與 AI 模型能夠據此進行分析、預測與自動化操作。常見的顧客標籤類型包括:
• 消費行為類:高價值客、沉睡客、首購客、回購客
• 風險類:流失風險客、退訂傾向族群
• 興趣偏好類:特定品類愛好者、季節性購買者
• 行為意圖類:高頻瀏覽未購買者、加入購物車未結帳者
這些標籤不只是靜態的分類結果,更是行銷自動化與 AI 預測模型的觸發條件與輸入依據。標籤的精準度,可以直接決定了後續個人化溝通、廣告受眾設定與流失預警的執行品質。換句話說,顧客貼標做得好不好,最終會反映在每一次行銷行動的轉換效率上。
三、顧客貼標為什麼重要?
• AI 行銷工具全面普及,但資料的輸入品質決定最終分析結果:
現在各種 AI 行銷平台都在說自己能自動優化、自動個人化,但這些系統的前提,是你有乾淨且有意義的顧客數據。垃圾進,垃圾出,這在 AI 時代依然成立。
• 消費者對個人化的期待越來越高:
不相關的廣告會讓人反感,真正貼近需求的溝通才能建立信任。而做到這件事,需要你真的理解每一個顧客現在在哪個購買旅程的位置。
→ 企業之間的差距,越來越不是誰有更多錢買廣告,而是誰對自己的顧客理解得更深。顧客貼標,正是這種理解力的基礎建設。
四、可行動的顧客貼標引擎 :Ln{360°}
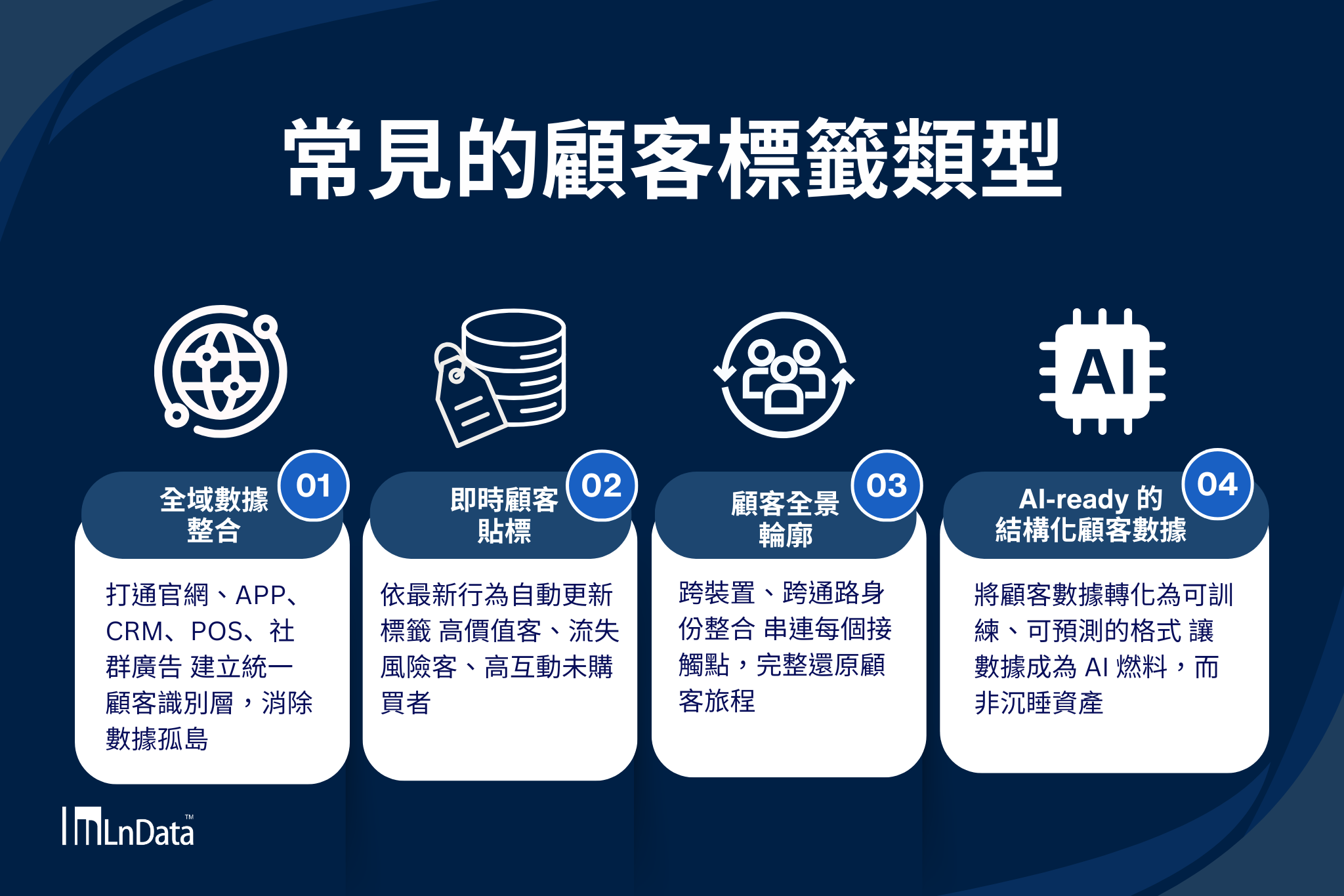
Ln{360°} 不是單純的 CDP,而是一個讓顧客貼標真正可行的基礎設施。
全域數據整合 | 打通官網、APP、CRM、POS、社群廣告,建立統一的顧客識別層。數據孤島的問題從這裡開始解決,讓你第一次看到完整的顧客全貌。
即時顧客貼標 | 根據顧客的最新行為,自動更新標籤狀態。高價值客、流失風險客、高互動未購買者,不再只是 Excel 裡的靜態欄位,而是隨顧客行為即時刷新的動態輪廓。
顧客全景輪廓 | 提供跨裝置、跨通路的真實身份整合,讓同一個顧客在不同接觸點的行為,能夠被串連成完整的旅程。無論顧客從哪個渠道進來,你都能認得出他是誰。
AI-ready 的結構化顧客數據 | 不只是建立標籤,而是把顧客數據轉化成 AI 能理解、能訓練、能預測的結構化格式,讓你的顧客數據真正成為企業的 AI 燃料,而不是堆在系統裡的沉睡資產。
結語、貼標不只是技術成本,是必要基礎設施
很多企業把顧客貼標、AI 訓練當成有預算或時間再做的事,這個思維在現在的市場環境裡代價很高。
當廣告成本持續上漲,當平台給的流量越來越貴,當顧客的注意力越來越難取得,你能做的最有效率的事,不是去搶更多流量,而是把已經進來的顧客真正分析透徹。資料貼標是 AI 學習的起點,顧客貼標是精準行銷的起點。
未來 AI 的競爭,核心不只是誰有更強的模型,而是誰更理解自己的顧客。而那份理解,從你現在怎麼對待自己的數據就開始了。
想了解如何精準鎖定你的目標客群嗎?
📩 立即諮詢 ❯❯❯ https://lndata.com/contact




